Building the BrainGrid Way: From Idea to Shipped Software
A clear mental model for turning ideas into working software with AI. Four stages — Idea, Epic, Requirements, Build — no guesswork, no restarts.

A clear mental model for turning ideas into working software. Four stages, no guesswork: Idea, Epic, Requirements, Build.
A founder messaged us last month. She'd spent six weeks of evenings and weekends building a booking app for independent dog walkers. Screens designed. Rough prototype working. Real conversations with walkers in her neighborhood who wanted it.
Then she hit a wall.
"Every time I add something new, something old breaks. I asked the AI to add payments and it rewrote my booking flow. I have three different versions of user profiles and I don't know which one is right anymore. I've started over twice."
Two restarts. The idea was solid. The tools were capable. She'd skipped the thinking and jumped straight to the building.
BrainGrid exists to close that gap.
#Idea. Epic. Requirements. Build.
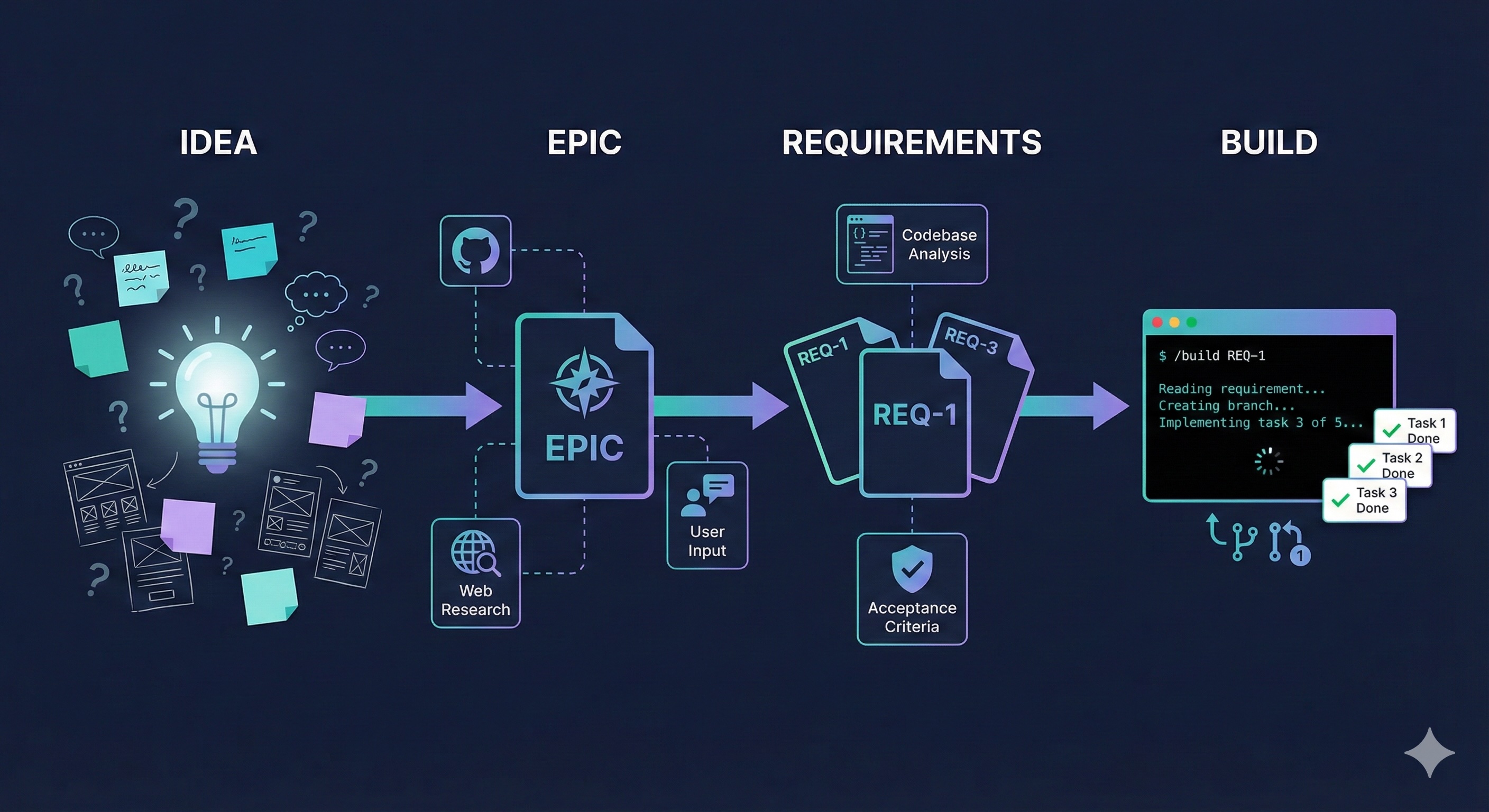
- Idea — messy thought becomes clear direction. Opens in your browser. Nothing to install.
- Epic (a chapter of your product) — what to build and in what order
- Requirements (a single feature, fully described) — what "done" looks like
- Build — ship it with Claude Code, one command at a time
Here's what this looked like for her.
#Stage 1: Idea
She typed her rough idea into BrainGrid: "Booking platform for independent dog walkers. Local, not corporate. Walkers set their own rates. Owners book based on neighborhood and reviews."
The planning agent didn't start building. It pushed back:
"Who's your primary user — the dog owner or the walker? Which one do you need to attract first to make the marketplace work?"
"How do owners verify a walker is trustworthy? Background checks? Reviews? A rating threshold before they can accept bookings?"
"Rover, Wag, and Care.com all serve this space. What specifically makes a local-first model better — and for which neighborhoods?"
Not template questions. The agent had already pulled Rover's 35% service fee, Wag's walker churn rates, and three local alternatives in her city. It used that research to press her the way a sharp co-founder would over coffee.
Twenty minutes later, she had something six weeks of coding never gave her: a clear picture of who she was building for (dog owners in walkable neighborhoods where Rover felt impersonal), her real differentiator (hyper-local, walker-first), and what she was deliberately not building (GPS tracking, enterprise features, anything that competes on scale).
#Stage 2: Epic
Her product broke into four epics — four chapters:
- Walker profiles and verification — the foundation everything else depends on
- Search and booking — the core experience
- Payments — how money moves
- Reviews and trust — what keeps people coming back
The agent mapped the dependencies: you can't search for walkers who don't have profiles. You can't process payments for bookings that don't exist. You can't review a walk that hasn't happened. Each epic builds on the one before it.
This is where her first two attempts broke. She'd jumped straight to the booking flow — the exciting part — without nailing down how walker profiles worked. When she added payments, the AI had no context for what a "booking" contained, so it invented its own version. Two data models. Conflicting assumptions. Restart.
Epics prevent that. Each chapter declares what it owns. Epic 2 knows walker verification lives in epic 1. It references those decisions instead of reinventing them.
#Stage 3: Requirements
Each epic breaks into requirements — the individual features. If an epic is a chapter, a requirement is a scene. One clear thing that needs to exist.
For "search and booking," BrainGrid generated:
- REQ-1: Search for walkers by neighborhood and availability
- REQ-2: View walker profile with rates, bio, and verification status
- REQ-3: Book a walk for a specific date, time, and dog
- REQ-4: Send booking confirmation to both owner and walker
These aren't sentences. They're full specifications. REQ-3 included details she hadn't considered: what happens when two owners book the same slot? What if a walker hasn't set availability? What error appears if payment isn't connected?
She didn't write those edge cases. The agent did — because it had read every sibling requirement, checked what REQ-1 and REQ-2 already decided, and filled the gaps. Nothing contradicted. Nothing re-decided.
Every requirement gets a readiness score from 1 to 5. REQ-3 came back as a 3. The agent flagged a missing cancellation policy. She typed one sentence: "Owners can cancel free up to 2 hours before the walk. After that, the walker keeps 50%." Score flipped to 5. Ready to build.
One sentence. The difference between code that works and code you argue with later.
#Stage 4: Build
The next day, she opened Claude Code and typed:
1/build REQ-3
BrainGrid fetched the full requirement, created a branch on GitHub (feature/REQ-3-book-a-walk), and Claude Code broke the work into four tasks — each one sequenced with dependencies. Then Claude started building. No confirmation prompts. No waiting. Task by task:
1TASK 1: feat: Create bookings table with time-slot constraints ✓ 2TASK 2: feat: Build booking API with conflict detection ✓ 3TASK 3: feat: Add booking form with date/time picker ✓ 4TASK 4: feat: Send booking confirmation to owner and walker ✓
Database first. API second. Frontend last. Each task was implemented, validated, committed, and updated in BrainGrid before the next one started — the same ordering she'd failed to maintain manually across two restarts, now handled automatically because the requirement specified the dependencies upfront.
Before it finished, the agent verified every acceptance criterion she'd written. The time-slot conflict check returned her exact error message: "This walker is already booked at that time. Here are their next available slots." The cancellation policy she'd added to reach readiness 5 was implemented word for word. Only after every criterion checked out did the requirement move to review.
She stopped debugging. She started reviewing. Not as a programmer hunting bugs, but as a product owner checking work against her own words. You don't write the code. You answer the questions. BrainGrid ships the feature.
#The loop
She shipped REQ-3 and moved to REQ-4. Then the next epic. Each cycle ran faster — the system already knew her data model, her naming conventions, every decision from the previous requirements.
By week three, she had a working MVP in front of real dog walkers in Park Slope. Not a prototype. Not a demo. And when those walkers started requesting features — schedule changes, recurring bookings — she didn't panic. She typed each one into BrainGrid and watched it move through the same four stages, faster each time, because the system already knew everything she'd built.
Most builders think their bottleneck is code. It isn't. The bottleneck is knowing what to build, in what order, with enough precision that the result actually works. BrainGrid front-loads that thinking. By the time you type /build, the hard decisions are already made.
Type your idea in like she did. Watch your first epic land in three minutes. No installs. No code.
About the Author
Tyler Wells is the Co-founder & CTO of BrainGrid, where we're building the future of AI-assisted software development. With over 25 years of experience in distributed systems and developer tools, Tyler focuses on making complex technology accessible to engineering teams.
Want to discuss AI coding workflows or share your experiences? Find me on X or connect on LinkedIn.
Keep Reading



Ready to build without the back-and-forth?
Turn messy thoughts into engineering-grade prompts that coding agents can nail the first time.
Re-love coding with AI