Why we switched from Claude web search to Exa for the BrainGrid agent
Claude's web search tool responds with encrypted content, which complicated our implementation. Here's the approach we took with Exa in under 100 lines.

We hit a problem last week that made us rethink our entire approach to web search in AI agents.
Our requirements planning agent needed to look up best practices, documentation and be able to do research. You know, the usual stuff, how to properly implement OAuth flows, current React patterns, API design guidelines. Claude's built-in web search seemed perfect. We use Anthropic models everywhere, so why not use their search too?
Turns out, there was a really good reason not to.
The issue wasn't performance or cost. It was something we never saw coming: encryption. Claude encrypts web content, which sounds great until you realize your agent can't actually understand what is going on. We discovered this while building our requirements agent to help developers write better specs. The agent would search for API docs, find exactly what it needed, then... nothing. Just encrypted blobs where structured data should be. Hard to figure out what content is actually there. One additional wrinkle is that we use Google's Gemini for certain tasks of our agent, and Gemini doesn't understand Claude's encrypted content.
This is how we moved forward with Exa in under 100 lines of code.
#How Claude's encryption broke our documentation workflow
Let me paint you a picture. Your agent searches for "Stripe create payment intent API". Claude finds the perfect page. But here's what comes back:
1{ 2 "content": { 3 "encrypted": "2f3a9b8c4d5e6f7a8b9c0d1e2f3a4b5c...", 4 "index": "encrypted_index_abc123..." 5 }, 6 "citation": { 7 "url": "https://stripe.com/docs/api/payment_intents/create", 8 "title": "Create a PaymentIntent" 9 } 10}
That encrypted field? It contains all the good stuff. The request parameters, the response schema, the code examples. Everything your agent needs to write a proper requirement. But it's locked away.
We tried working around it. Maybe we could use the citations to reconstruct the content? Nope. Citations give you tiny snippets, not the full API schema. Maybe we could chain multiple searches? That just gave us more encrypted blobs.
We spent hours trying different approaches. Parse the citations more cleverly. Search for smaller chunks. Use different query patterns. Nothing worked. The encryption was doing exactly what it was designed to do, protecting content. Just not in a way that worked for our use case.
#Enter Exa: a search engine built for AI applications
That's when we found Exa. It bills itself as "search built for AIs," and honestly, that's exactly what it is.
Here's the same Stripe API search with Exa:
1{ 2 "url": "https://stripe.com/docs/api/payment_intents/create", 3 "title": "Create a PaymentIntent | Stripe API Reference", 4 "text": "POST /v1/payment_intents\n\nCreates a PaymentIntent object...\n\nParameters:\n- amount (required): Amount in cents\n- currency (required): Three-letter ISO code\n- payment_method_types: Array of payment methods...", 5 "highlights": [ 6 "amount integer Required", 7 "currency string Required", 8 "automatic_payment_methods object" 9 ] 10}
See the difference? Actual content. Parseable, structured, immediately useful content.
But Exa isn't just unencrypted Claude search. It's built differently. The neural search understands technical queries in a way traditional search doesn't. Ask for "React Server Components data fetching patterns" and it finds the exact section in the docs, not just pages that happen to contain those words.
The best part? It plugged right into our Vercel AI SDK setup. We were already using AI SDK v5 (after our migration adventure). Exa has first-class support for it. Total integration time: one afternoon.
#The implementation: web search and web page reading in two tools
Here's where it gets interesting. We didn't just replace Claude's search, we built something better.
The code below shows the initial implementation. A brand new tool that would take care of:
- Searching the web
- Using the results to get the most relevant content
1// Web search for finding relevant docs and best practices 2const webSearchTool = tool({ 3 description: 'Search the web for relevant information', 4 inputSchema: z.object({ 5 query: z.string().min(1).max(100), 6 num_results: z.number().min(1).max(10), 7 max_characters: z.number().min(1).max(10000) 8 }), 9 execute: async ({ query, num_results, max_characters }) => { 10 const { results } = await exa.searchAndContents(query, { 11 livecrawl: 'always', 12 numResults: num_results, 13 }); 14 return results.map(result => ({ 15 title: result.title, 16 url: result.url, 17 content: result.text?.slice(0, max_characters) ?? '', 18 publishedDate: result.publishedDate, 19 })); 20 }, 21});
But search alone wasn't enough. What happens if the user wants to attach a web page as context for the agent? Well, we can fortunately add a very simple tool so the agent is able to read a web page given a URL the user can provide:
1// Read full web pages when agents need complete context 2const readWebPageTool = tool({ 3 description: 'Read a web page and return the content', 4 inputSchema: z.object({ 5 url: z.string().url() 6 }), 7 execute: async ({ url }) => { 8 const { results } = await exa.getContents(url); 9 return results; 10 }, 11});
While giving the agent the ability of surfing the web looking for relevant content is extremely powerful, allowing users to tell the agent where to search for relevant information such as API docs or best practices guides is even more powerful. And all of this with no encryption and no parsing headaches. Just clean, plain documentation ready for requirement writing.
We also discovered Exa's livecrawl feature, which forces fresh content retrieval. Critical for API docs that change frequently. No more cached responses from six months ago.
#Results: faster, cleaner, more reliable requirement generation
The experience speaks for itself, our agent is now able to do research and write better requirements. It can do branched searching to explore different aspects and if it needs to dig deeper, it can use the readWebPage tool to get the complete context.
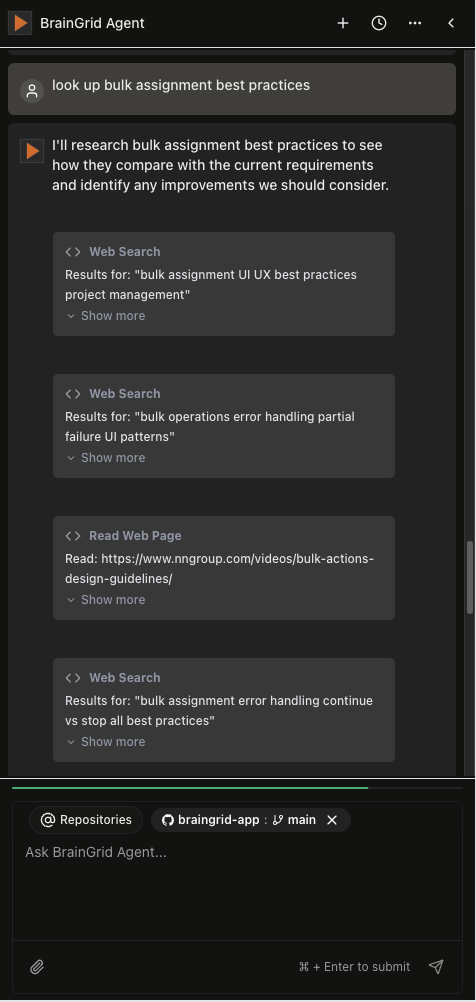 The BrainGrid agent searching for best practices
The BrainGrid agent searching for best practices
The BrainGrid agent parses the results and gives actionable responses, like figuring out what best practices the current requirements document already implements and what is missing.
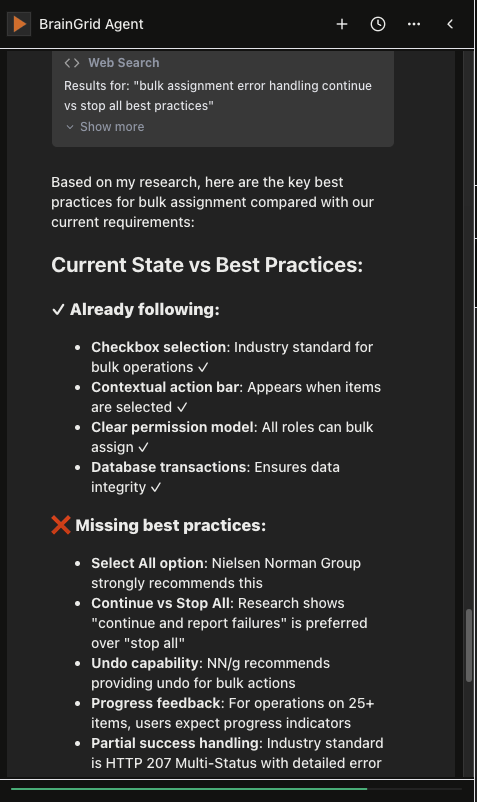 The BrainGrid agent using search result to suggest improvements
The BrainGrid agent using search result to suggest improvements
It also doesn't take everything it reads, it recommends the most impactful best practices for the requirement that you're working on.
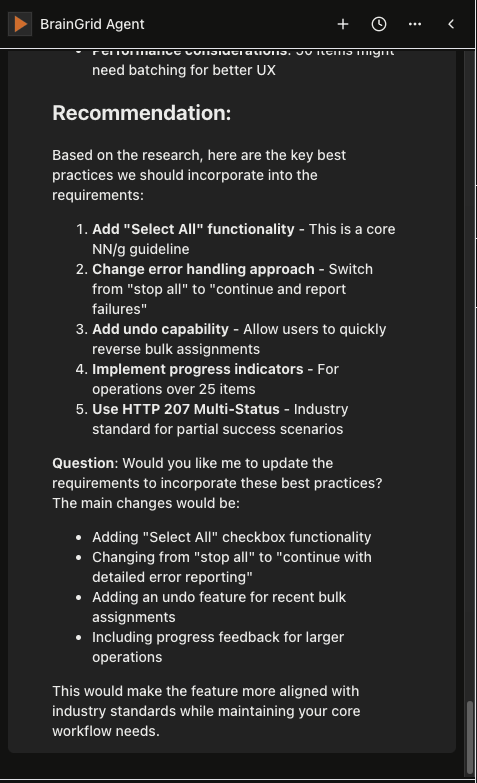 The BrainGrid agent synthesizing findings in the context of the current requirements document.
The BrainGrid agent synthesizing findings in the context of the current requirements document.
But the real win? Our requirements got better. Way better.
This level of detail means developers spend less time asking clarifying questions and more time building. Requirements are actionable from day one.
One unexpected benefit: the agent exposes its sources. When it recommends a specific approach, you can see exactly what search results it got and what pages it read. Developers can verify the reasoning, learn something new, or dig deeper if needed.
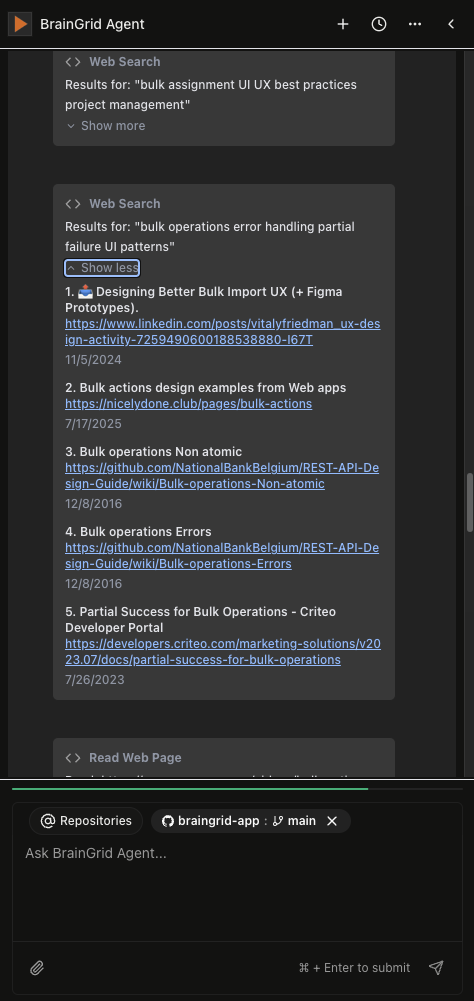 The BrainGrid agent's web search card exposing search results
The BrainGrid agent's web search card exposing search results
#The bigger picture
This whole experience taught us something important. When building AI tools for developers, the quality of your data access matters as much as your model choice.
Claude's web search works great for general queries where you are using exclusively Claude models. But for more sophisticated agents that leverage different models for different tasks with the same context, you need full control over what is going into the context.
If you're hitting similar walls with encrypted content, give Exa a look. The migration is straightforward, especially if you're already on Vercel AI SDK. Our entire switch took less than 100 lines of code across two PRs.
Building AI developer tools? We should talk. We're solving these problems every day at BrainGrid, turning messy ideas into AI-ready requirements. Try it yourself and see what properly researched AI-ready requirements look like.
Keep Reading



Ready to build without the back-and-forth?
Turn messy thoughts into engineering-grade prompts that coding agents can nail the first time.
Re-love coding with AI